Übersicht
Im April 2024 kündigte GP2 die siebte Datenfreigabe in Kooperation mit AMP® PD auf der Terra- und der Verily-Plattform an. Diese Freigabe umfasst über 9000 zusätzliche genotypisierte Teilnehmende.
- Die Genotyp-Array-Daten, einschließlich Proben mit lokalen Einschränkungen, umfassen nun insgesamt 54.180 genotypisierte Teilnehmende (28.729 mit Parkinson-Erkrankung, 15.834 Kontrollpersonen und 9617 „sonstige“ Phänotypen).
- Abzüglich der Proben mit lokalen Einschränkungen beträgt die Zahl nun 40.740 (20.507 mit Parkinson-Erkrankung, 11.841 Kontrollpersonen und 8.392 „sonstige“ Phänotypen).
- Zu 17.496 Personen mit tiefen klinischen Phänotypisierungsinformationen liegen auch passende genetische Informationen vor.
Was ist in dieser Freigabe neu?
- Zusätzliche genotypisierte und imputierte Proben
- Zusätzliche klinische Daten für rund 4.911 Personen
DSGVO-Proben mit lokalen Einschränkungen über die Verily Viewpoint Workbench
Im Rahmen unserer Zusammenarbeit mit der Verily Viewpoint Workbench setzen wir das Pilotprojekt zur Gewährung eines Zugangs zu lokal eingeschränkten Proben (d. h. Proben, die unter die Allgemeine Datenschutzgrundverordnung, DSGVO, fallen) fort.
Da GP2 aktuell weiter an Lösungen für den Austausch DSGVO-geschützter Daten arbeitet, sind Daten der 7. Freigabe mit regionalen Einschränkungen nur für Mitglieder des GP2-Forschungsverbunds sowie Partner verfügbar. Im Zuge der weiteren Tests und Implementierung Anfang 2024 wird diese Lösung dann der breiteren Forschungsgemeinde zur Verfügung stehen. Sämtliche Proben der 7. Freigabe sind auf der Workbench zu finden, während alle Proben der 7. Freigabe, die nicht den DSGVO-Anforderungen unterliegen, auf der Community Workbench auf Terra zu finden sind (so wie alle vorherigen Freigaben). Wenn Sie Zugang zur gesamten Freigabe auf VWB erhalten möchten, müssen Sie:
- über einen bewilligten GP2-Tier-2-Zugang verfügen,
- das Antragsformular für DSGVO-Proben ausfüllen,
- Mitglied des GP2-Forschungsverbunds sein (beitragende Kohorte, GP2-Partner oder Projektanalyse-Teammitglied).
Klinische Daten
Diese Freigabe enthält tiefe klinische Phänotypisierungsdaten für weitere 4.911 Personen. Diese Informationen umfassen:
- Alter bei Diagnose und Ausbruch
- Primäre, aktuelle und letzte Diagnose
- Kognitive Tests wie der Mini-Mental Status-Test (MMST) und der Montreal-Cognitive-Assessment-Test (MoCa)
- Von der Movement Disorder Society gesponserte Überarbeitung der Unified Parkinson’s Disease Rating Scale (MDS-UPDRS)
- Detaillierte „sonstige“ Phänotypen wie etwa Lewy-Körper-Demenz (LBD)
In dieser Freigabe liegen zu jeder der 17.496 Personen mit klinischen Informationen auch passende genetische Informationen vor.
Individuen-spezifische Daten:
Wir erfassen nun die Daten von insgesamt 87 Kohorten; 14 davon sind neu in dieser Freigabe. Weitere Informationen zu den bereitgestellten Kohorten finden Sie im GP2 Cohort Dashboard.
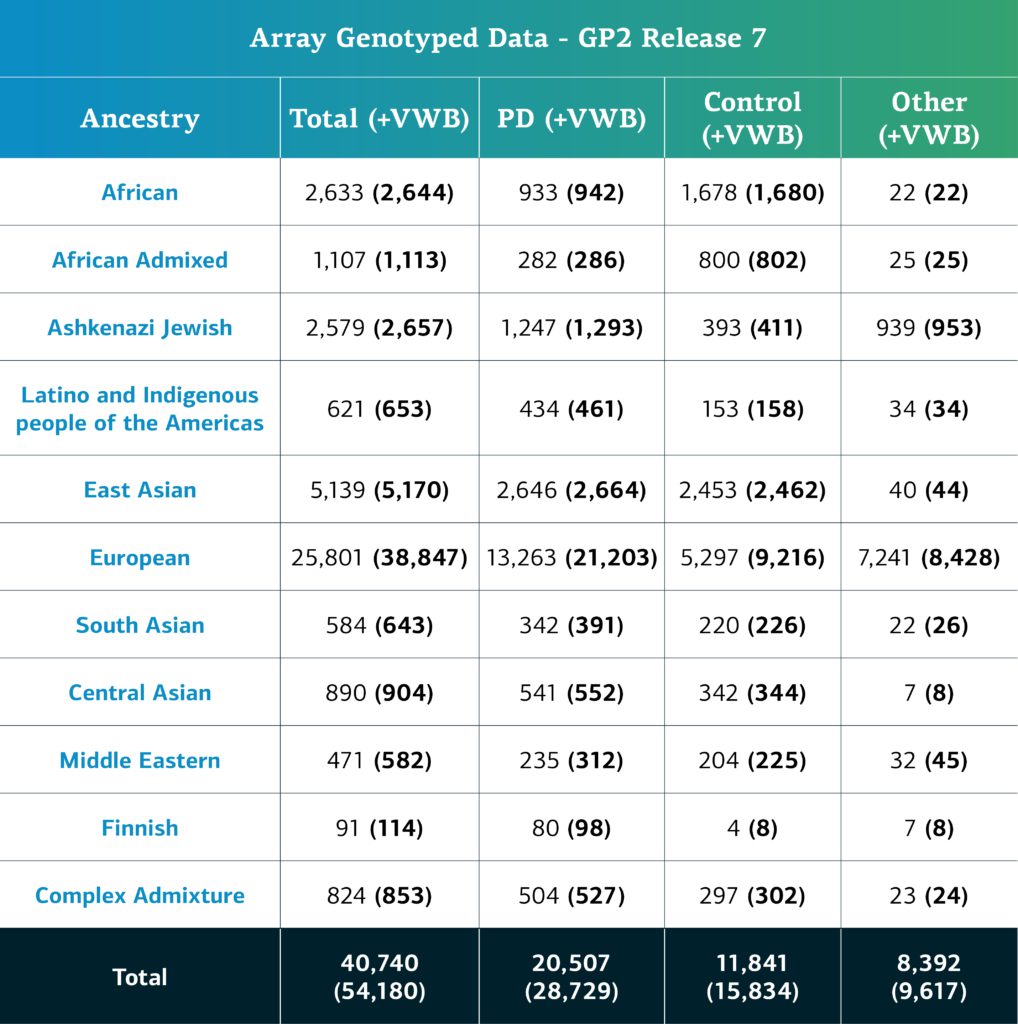
Die genetisch determinierte Abstammung von Array-genotypisierten GP2-Teilnehmenden wird in 11 Abstammungsgruppen gegliedert; die Tabelle unten gibt Aufschluss über die genetisch determinierte Abstammung der genotypisierten Teilnehmenden in dieser Freigabe, welche die Qualitätskontrolle durchlaufen haben und imputiert wurden. Diese Zahlen beinhalten Proben aus früheren Freigaben, die unter Verwendung der neuen Cluster-Datei neu geclustert wurden und die Qualitätskontrolle durchlaufen haben, sowie die neu genotypisierten und gemeinsam genutzten Proben, die nur in dieser aktuellen Freigabe enthalten sind.
Gesamtgenomsequenzen mit Aufruf durch DeepVariant-GLnexus
Weitere GP2-Sequenzierungsdaten werden für das 3. Quartal 2024 erwartet.
Durch zukünftige Datenfreigaben wird sich die Vielfalt der verfügbaren Teilnehmenden weiter erhöhen. Auf unserem Cohort Dashboard können Sie sich über den Fortschritt unserer Arbeiten informieren. Wer bereits über einen Tier-2-Zugang verfügt, kann die Daten in unserem Cohort Browser ansehen, der bereits in einem früheren Blogbeitrag vorgestellt wurde.
Wie immer finden Sie weitere Details zu Pipelines, Daten und Analysen in der README-Datei zur jeweiligen GP2-Freigabe!