En diciembre del 2021, el GP2 anunció su primera aportación de datos del GP2 en la plataforma AMP® PD. Los datos disponibles hacen referencia a 4908 participantes (3434 con EP y 1474 sin EP) de las cohortes de CORIELL, Baylor College of Medicine (BCM) y BCM-University of Maryland (UMD). La ascendencia determinada genéticamente de los participantes del GP2 se categoriza en ocho grupos. En la siguiente tabla presentamos los detalles de la ascendencia determinada genéticamente de los participantes de la primera aportación del GP2. 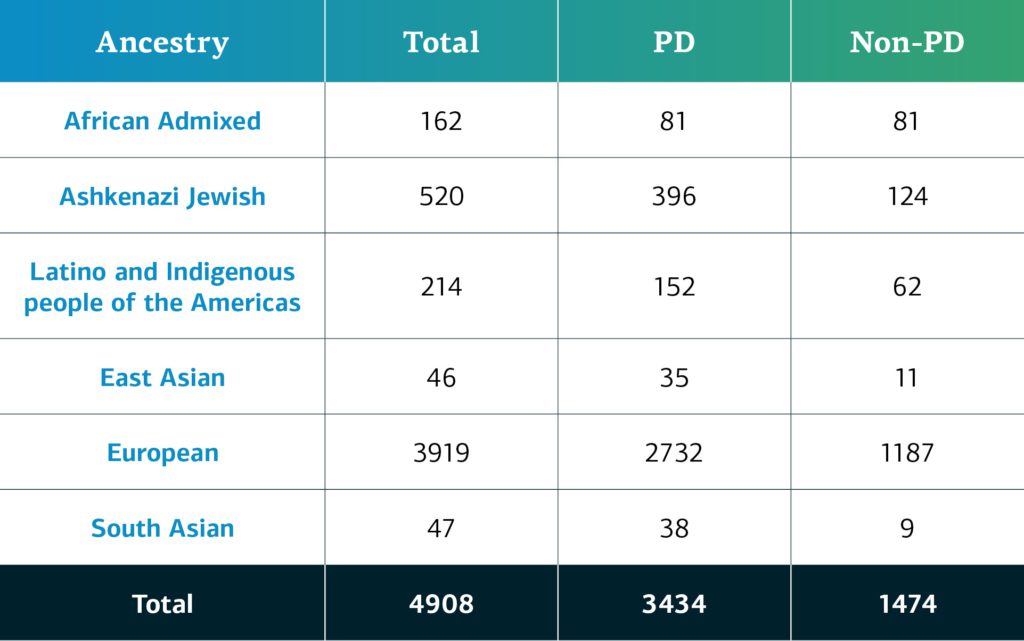 En futuras aportaciones, seguiremos ampliando la diversidad de los participantes. Les invitamos a visitar nuestro panel para conocer nuestro progreso.
En futuras aportaciones, seguiremos ampliando la diversidad de los participantes. Les invitamos a visitar nuestro panel para conocer nuestro progreso.
Datos genotipados
Todos los datos se genotiparon en Illumina NeuroBooster Array, una matriz específicamente diseñada para genotipar variantes de enfermedades neurodegenerativas en poblaciones diversas. Los datos se procesaron de acuerdo con los protocolos estándares de Illumina. El control de calidad de los datos corrió a cargo del GP2, que implementó un flujo de CC de código abierto. Luego, los datos se imputaron con TOPMed, separados por grupos de ascendencia. Todos los duplicados conocidos se descartaron, pero las muestras relacionadas no se eliminaron, en aras de facilitar la flexibilidad en los análisis comunitarios. Para más información sobre nuestro proceso de CC, encontrará el flujo de trabajo detallado en nuestra página asociada de GitHub.
Datos clínicos
Se armonizaron los datos clínicos para crear un conjunto de datos clínicos del GP2 unificado. Los requisitos mínimos de los datos clínicos incluyen la información demográfica, la categoría de reclutamiento y los antecedentes familiares. Para más información sobre los niveles de requisitos de los datos básicos del GP2, véase el documento «Clinical Data Core Data Set», en la sección de recursos de nuestro sitio web. Se puede acceder a los datos a través de la plataforma Terra. Para instrucciones sobre cómo acceder a los datos del GP2, consulte nuestro artículo de blog «Applying for GP2 Data Access on the AMP® PD Platform». Los productos de datos siguientes están disponibles en Terra, y forman parte de la primera aportación del GP2:
- Acceso a los datos de nivel 1
- Resumen estadístico del GWAS sobre enfermedad de Parkinson más reciente (no incluye las muestras 23andMe de Nalls et al. 2019).
- Acceso a los datos de nivel 2
- Datos genotipados brutos: Archivos .pgen de PLINK2 para cada grupo de ascendencia con todas las muestras que hayan superado el control de calidad previo a la imputación
- Datos genotipados imputados: Archivos .pgen de PLINK2 imputados desde el panel de referencias TOPMed (con datos que hayan superado ciertos filtros de control de calidad, detallados en el archivo README que acompaña la aportación de datos)
- Metadatos: proporcionan información relativa a los resultados del CC y a las predicciones de ascendencia
- Datos clínicos: campos de datos clínicos y diccionario de datos clínicos relevantes
Esperamos que nuestra aportación de datos sea un recurso de interés para la comunidad de investigación de la enfermedad de Parkinson. Seguiremos mejorando nuestros procesos y ya estamos trabajando en las próximas novedades. 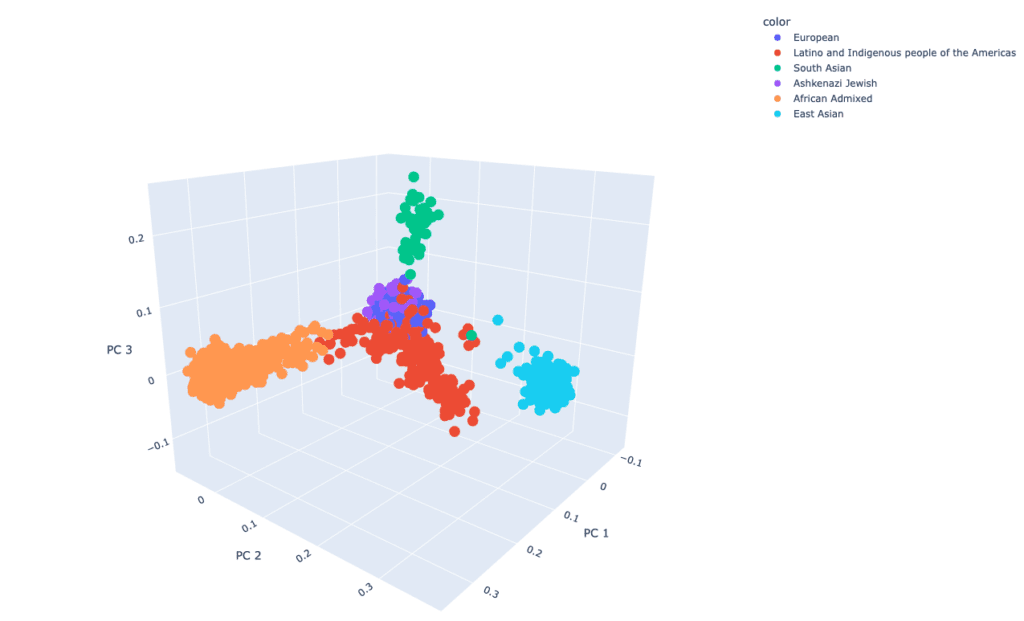 Este blog es obra conjunta de Hampton Leonard, Mike Nalls, Yeajin Song y Dan Vitale. Visite la página del Grupo de Trabajo de Análisis de Datos sobre Enfermedad de Parkinson de Etiología Compleja del GP2 para conocer a los autores.
Este blog es obra conjunta de Hampton Leonard, Mike Nalls, Yeajin Song y Dan Vitale. Visite la página del Grupo de Trabajo de Análisis de Datos sobre Enfermedad de Parkinson de Etiología Compleja del GP2 para conocer a los autores.