Overview
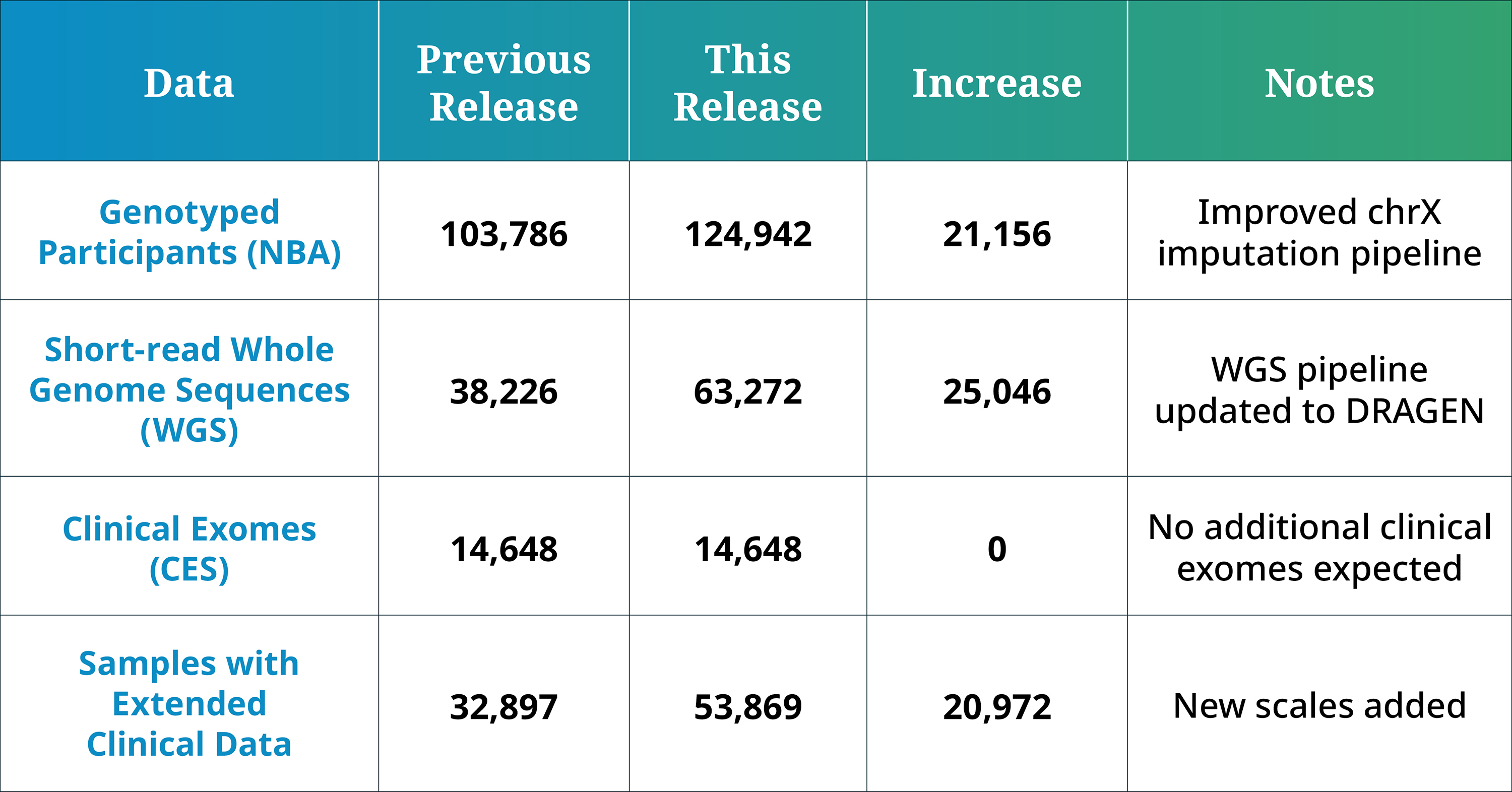
In July 2026, GP2 announced the 12th data release on the Terra and the Verily® Workbench platforms in collaboration with AMP® PDRD. This release includes 21,156 additional genotyped participants and 25,046 additional whole genome sequencing (WGS) participants.
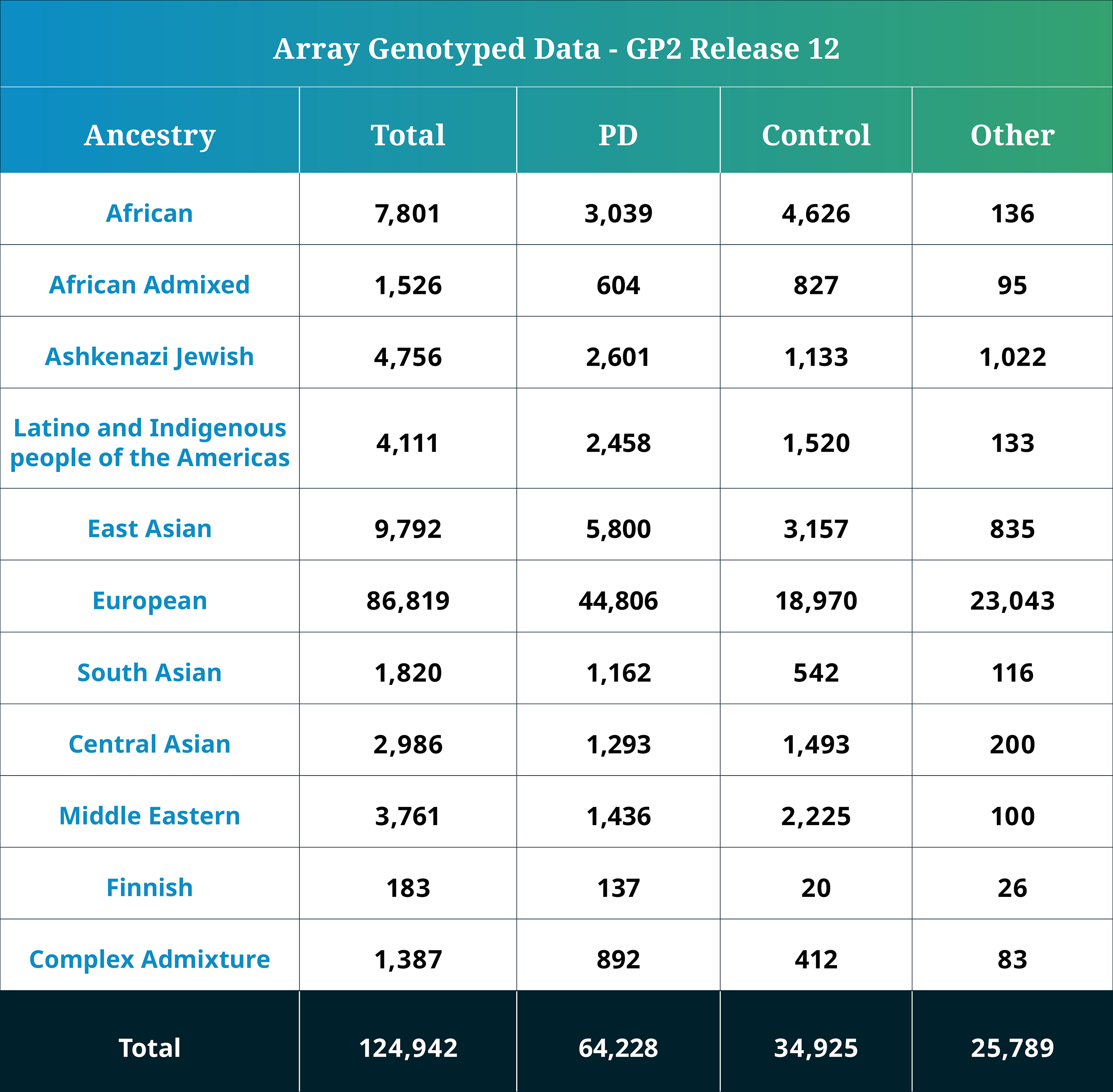
- The genotype array (NeuroBooster Array [NBA]) data, including locality-restricted samples, now consists of a total of 124,942 genotyped participants (64,228 PD cases, 34,925 Controls, and 25,789 “Other” phenotypes).
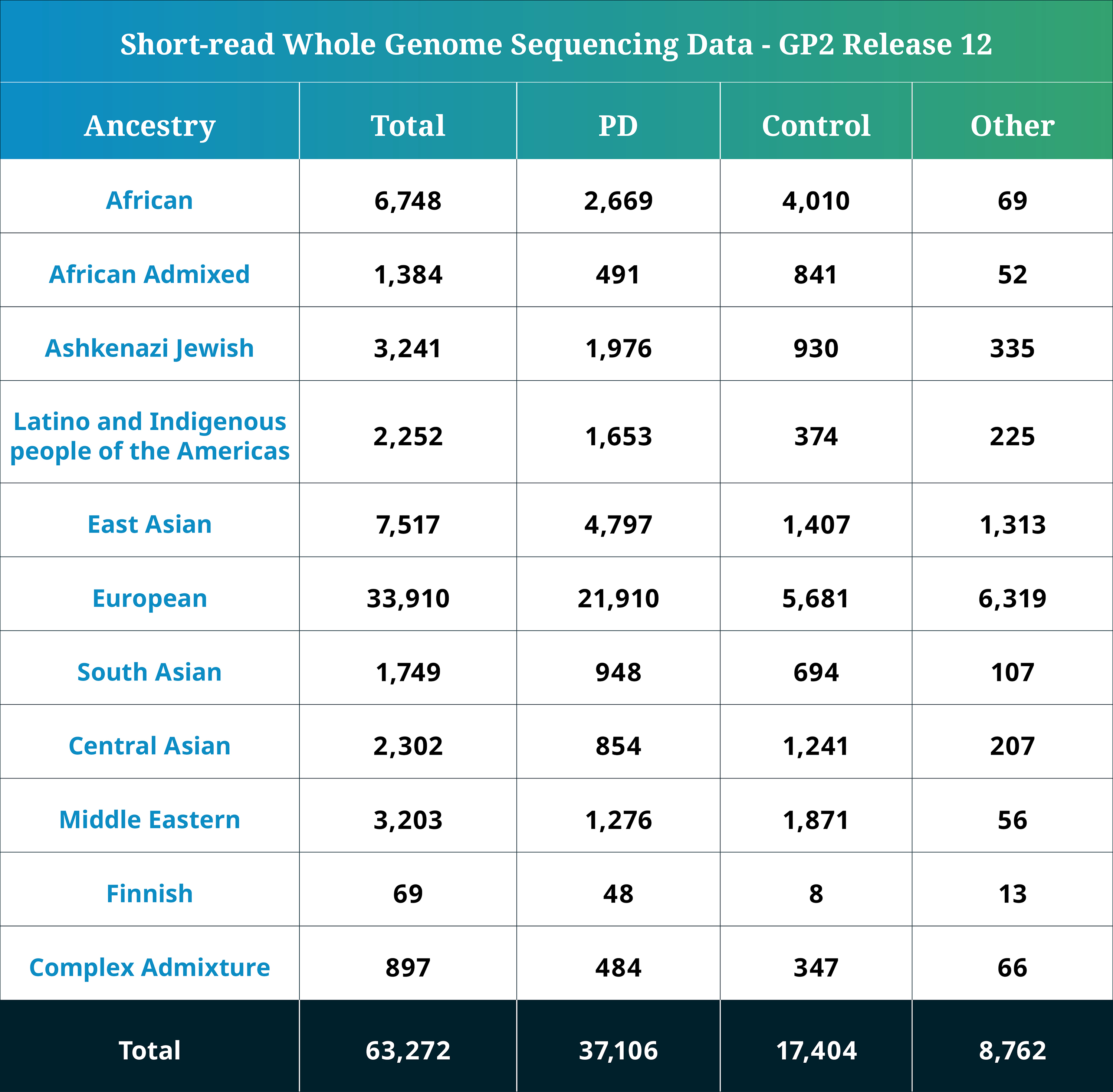
- The WGS data now consists of a total of 63,272 sequenced participants (37,106 PD cases, 17,404 Controls, and 8,762 Other phenotypes).
- The clinical exome data consists of 14,648 samples with PD.
- Of the 147,451 unique samples with genetic data (NBA, WGS, or clinical exome), 53,869 individuals also have additional extended clinical information.
Release At A Glance
What’s New In This Release?
Expanding Genomic Data
This release introduces a substantial expansion in the number of participants with available genetic data. We have added:
- 21,156 new participants with genotype array (NeuroBooster Array (NBA)) data
- 25,046 new participants with whole genome sequencing (WGS) data
- 20,972 new participants with extended clinical data
Upgraded WGS Pipeline: Migration from DeepVariant to DRAGEN
A major technical advancement in this release is the migration of our short-read WGS variant calling pipeline from DeepVariant to Illumina’s DRAGEN (version 4.4.7). DRAGEN offers improved sensitivity and specificity for variant detection, particularly in complex genomic regions relevant to Parkinson’s disease by integrating targeted callers for GBA1 and HLA. Additionally, DRAGEN facilitates mitochondrial variant calling through a continuous allele frequency pipeline, similar to somatic variant calling pipeline. The joint mitochondrial variant callset is now available per ancestry.
Improved Chromosome X Imputation Pipeline
Correctly handling the X chromosome in genotyping data requires extra care: males carry only one copy of most of the X, in the non-pseudoautosomal (non-PAR) region, making apparent heterozygous calls there biologically impossible. As part of ongoing GP2 research (preprint in preparation), we processed male and female samples separately, harmonized pseudoautosomal regional boundaries with the TOPMed-r3 reference panel, and performed sex- and region-specific imputation and file preparation. This removed invalid diploid calls in the male samples. To make the output easier to interpret, we further split PAR from non-PAR into separate files and preserved a haploid format in the non-PAR male files.
X-chromosome files are now available per ancestry as three separate files: 1) male PAR region, 2) male non-PAR region, and 3) female PAR & non-PAR region.
New Summary Statistics Now Available
We’ve made available several additional GWAS summary statistics datasets under Tier 1 (summary-level data access):
- Okubadejo et al’s GP2 African and African Admixed GWAS in Parkinson’s disease (preprint)
- Step et al’s South African XWAS in Parkinson’s Disease (preprint)
- Chu et al’s Taiwan GWAS in Parkinson’s disease (paper)
- GP2’s Sex-stratified GWASes in Parkinson’s disease (preprint)
Browser Updates
The GP2 genome browser displays variant and gene-level data from individuals of diverse ancestries. This browser has now been updated to reflect the samples included in R12. The updated version of the browser includes four main updates:
- Updated data from R10 to R12.
- Added gnomAD browser style ClinVar variants Track (ClinVar June 06, 2026 release).
- Expanded the available phenotypes to include PD, PSP, DLB, and MSA.
- Updated GBA1 variant calls using DRAGEN pipeline.
Learn more about the browser in Fang et al., 2026.
Clinical Data
For details regarding the clinical data gathered, refer to our data dictionary. You should also consult our README for guidance on the proper interpretation of clinical data and GP2 phenotypes.
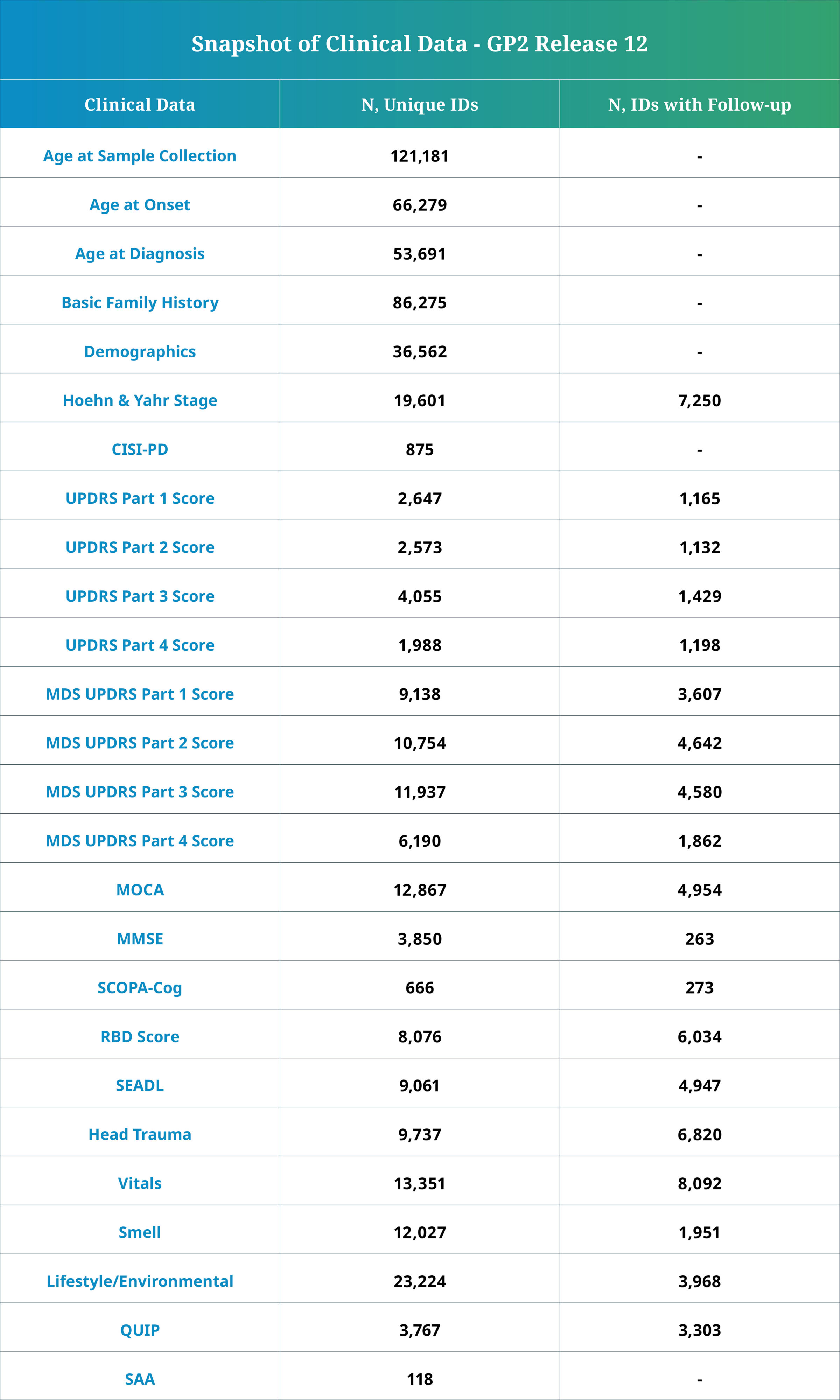
Release 12 contains clinical data for a total of 147,451 individuals with both genetic and core clinical data. Of these, 53,869 have deep clinical phenotyping available, including:
- Age at diagnosis and onset
- Primary, current, and latest diagnoses
- Cognitive exams such as the Mini-Mental State Examination (MMSE) and the Montreal Cognitive Assessment (MoCA)
- Movement Disorder Society-Sponsored Revision of the Unified Parkinson’s Disease Rating Scale (MDS-UPDRS)
- Lifestyle and environmental data
- Detailed Other phenotypes
Pathological diagnosis is also available for a subset of participants. We recommend checking the extended clinical information to make sure you are up to date on pathological diagnoses when using GP2 data.
Individual-Level Data
We now capture the data from a total of 184 cohorts. Please refer to the GP2 Cohort Dashboard for more information on the cohorts that have been shared.
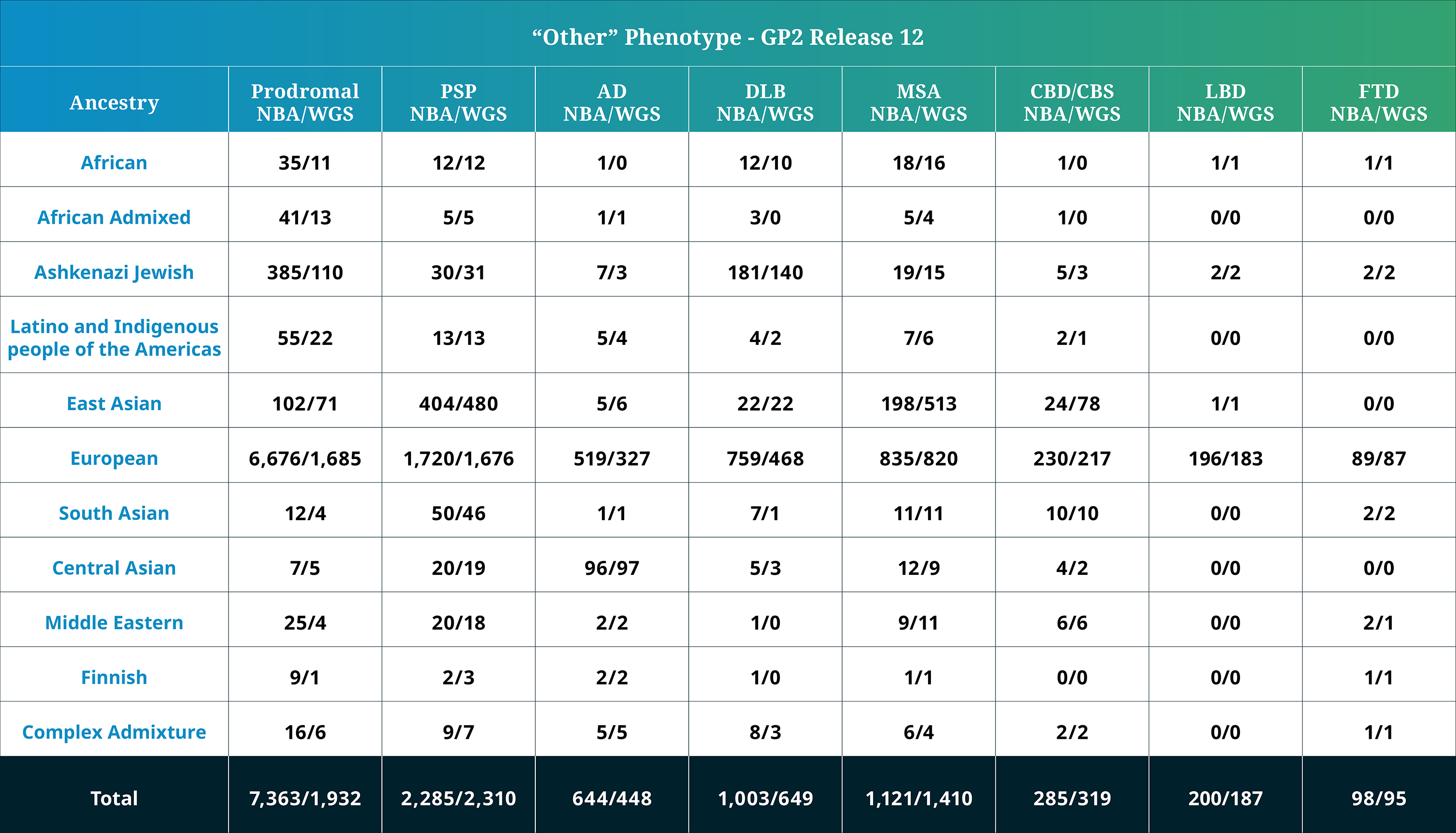
Genetically determined ancestry of array genotyped GP2 participants are characterized into 10 ancestry groups (in addition to a complex admixture history ancestry group); the tables below provide details of the genetically-determined ancestry of participants in this release that have passed quality control for array data and WGS data. These numbers reflect samples from previous releases, reclustered using the updated cluster file and subjected to quality control, as well as newly genotyped samples exclusive to this release. The final table provides information about the genetically determined ancestry of selected other, non-PD phenotypes.
Interested in Getting Access?

Locality-restricted GDPR samples via the Verily Viewpoint Workbench
We are continuing to grant access to locality-restricted samples, otherwise known as samples governed by the General Data Protection Regulation (GDPR) policy, through our collaboration with the Verily Viewpoint Workbench (VWB). To gain access to the full release on VWB you must have approved GP2 Tier 2 access (individual-level data access), you can apply for access here.
Future data releases will continue to grow the number and diversity of participants available. You can check out our dashboard to see our progress. For users with Tier 2 access already, you can explore the data further on our cohort browser, expanded on in a previous blog post.
As always, please refer to the README that accompanies each GP2 release for further details regarding recommendations for quality control, pipelines, data, and analyses!